DuckDB connector for pivot tables, charts
SeekTable includes built-in DuckDB engine which can be used as a SQL-compatible data source.
DuckDB is a fast in-process analytical OLAP database suitable for near-real time reporting and analytics. With DuckDB you can get high-performance low-cost DW that lives inside SeekTable! Also DuckDB may be useful for querying large CSV or JSON files directly (multiple files at once), Parquet files, Apache Iceberg format, Delta Lake, DuckLake, LanceDB and combining data from multiple data sources (JOIN/UNION) into a single report. Datasets are not obligated to be local files: they may be downloaded from URLs and/or a cloud storage (Amazon S3, Azure Blob, Google Cloud Storage).
DuckDB connector can be used as a client for MotherDuck cloud service. If you're looking for a self-service BI tool connected to MotherDuck, SeekTable is definitely a way to go.
Important: the full-featured DuckDB connector is available only in the self-hosted SeekTable version.
Due to security concerns/unpredictable server resources consumption only admin users can use unrestricted DuckDB connector (your SeekTable installation should have activated "System/users admin").
All users can use DuckDB connector in restricted mode (see below) and the MotherDuck connector.
DuckDB connector restricted mode
When in restricted mode, DuckDB connector can be used for data federation tasks:
- Local files cannot be accessed.
- Any extensions cannot be loaded.
- Data can be loaded only via cube_query SQL function. This function can return maximum 50000 rows (cloud SeekTable limitation; use on-prem deployment to handle 1M rows or more).
MotherDuck connector
MotherDuck is a cloud data warehouse based on the DuckDB SQL engine. It can be used for direct querying data files (CSV, JSON, Parquet) stored in Amazon S3, Azure Blob Storage, Google Cloud Storage or accessible via URL.
SeekTable has a separate MotherDuck connector (uses DuckDB as a client) to your cloud databases; an access to any local resources (say, local files) is prohibited.
This connector is available for all users:
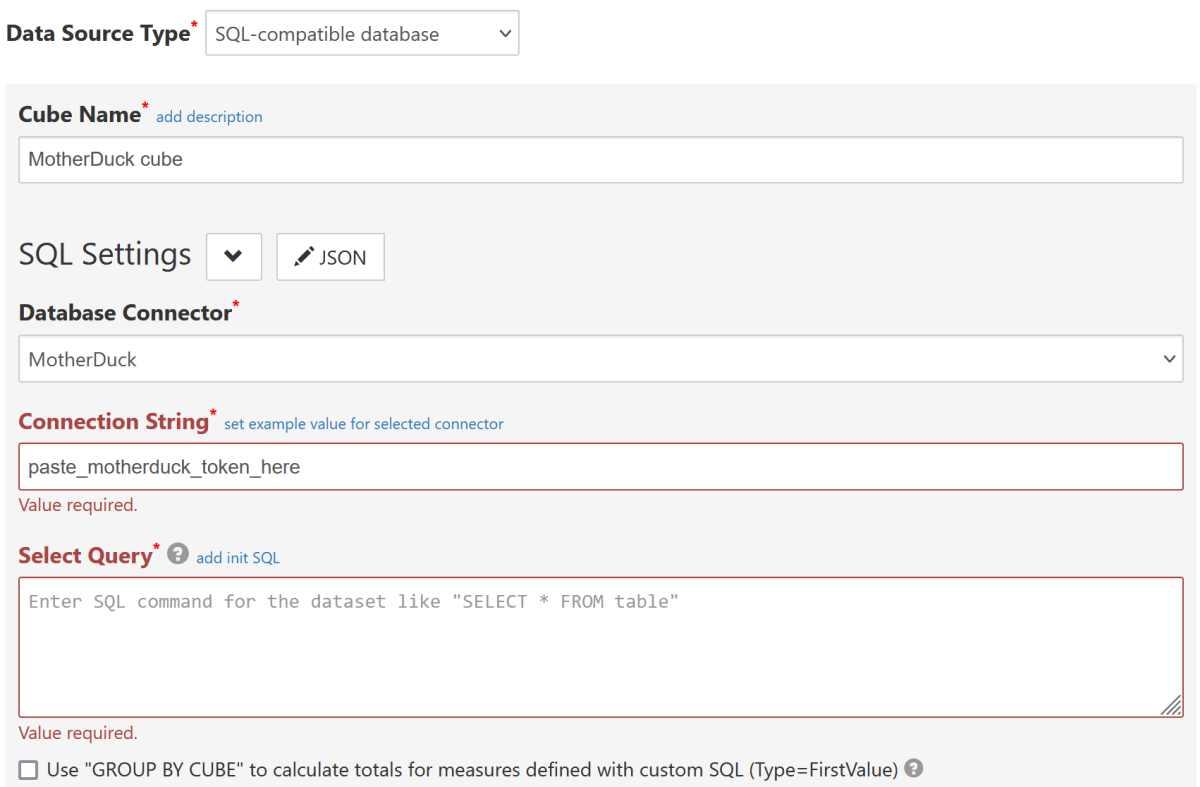
Connection String should be a valid MotherDuck token.
This connects SeekTable to all databases you have access to; this means that concrete database name should be specified as a part of table's name
in Select Query, for example:
select * from sample_data.nyc.service_requests
Enable DuckDB connector for self-hosted SeekTable
By default DuckDB connector is disabled in self-hosted SeekTable for security reasons (because unrestricted DuckDB engine can be used to access any local files). To enable DuckDB for your SeekTable installation:
- Edit docker-compose.seektable.env file (usually located in /opt/seektable)
-
Add this line:
SeekTable_ST__Connectors__DuckDB=true
-
Re-create SeekTable docker containers to apply this change (
docker compose stop+docker compose up -d). - Login as "admin" user, click "Connect to Database", choose "SQL-compatible database" (Data Source Type) and then "DuckDB" (Database Connector).
Note: only users with "admin" role can create unrestricted DuckDB-based cubes: this means that your SeekTable installation should have active "System/users admin" subscription. Regular (non-admin) users can access these cubes/reports in a safe manner via "Team sharing".
However, it is possible to enable 'restricted' DuckDB connector for all users:
- Edit docker-compose.seektable.env file (usually located in /opt/seektable)
-
Add this line:
SeekTable_ST__Connectors__DuckDBRestrictedEnableForAllUsers=true
- With 'restricted' DuckDB connector users cannot read local files, URLs or load any extensions (you can customize these restrictions according to your needs). Data can be loaded only via special cube_query SQL function (another SeekTable cubes).
-
Re-create SeekTable docker containers to apply this change (
docker compose stop+docker compose up -d).
DuckDB connector setup unrestricted: self-hosted SeekTable / admin users only
Connection String should be a valid connection string for DuckDB.NET driver; for example:
DataSource = /app-data/duckdb-files/test.db;ACCESS_MODE=READ_ONLY
| DataSource | Required |
Determines a data source type:
|
|---|---|---|
| ACCESS_MODE | Optional |
Specify READ_ONLY to make connection read only.
|
| threads | Optional |
Max number of threads to use (integer). For example: threads=4;.
|
| memory_limit | Optional | Limit RAM usage. For example: memory_limit=12GB. |
How to organize an access to local files unrestricted: self-hosted SeekTable / admin users only
DuckDB is a part of SeekTable's reporting engine and this means that all data processing is
performed inside seektable/pivotdataservice container.
To access data files located on your server (a host system where self-hosted SeekTable is deployed)
host's folder should be mounted in this way:
- Edit docker-compose.yml file (usually located in /opt/seektable)
-
Add a volume for "seektable/pivotdataservice" image that maps server's folder (for instance, /var/duckdb-files) to container's folder (/app-data/duckdb-files):
pivotdataservice: image: seektable/pivotdataservice:latest restart: always expose: - 5000 ports: - 5200:5000 volumes: - csv-files-volume:/app-data/csv-files - /var/duckdb-files:/app-data/duckdb-files env_file: - docker-compose.pivotdataservice.env depends_on: - "seektable"
You may use another folders, no special meaning in these names. -
Re-create SeekTable docker containers (
docker compose stop+docker compose up -d) to apply these changes. -
Now you can keep data files in host's
/var/duckdb-filesfolder (note that any other host's folder can be mounted) and then reference them as files located in/app-data/duckdb-files:- in the connection string:
DataSource = /app-data/duckdb-files/test.db;ACCESS_MODE=READ_ONLY
- in the cube's Select Query:
select * from read_csv('/app-data/duckdb-files/chicago-crimes.csv')
- in the connection string:
It is possible to mount multiple host's folders if needed.
How to combine data from multiple databases
DuckDB can be used as a query service that combines data from multiple databases (or local files) in the real-time.
Technically this is possible with ATTACH statements that connect 'remote' databases as local DuckDB databases (via an appropriate extension),
for example:
-
MySql extension:
INSTALL mysql; ATTACH IF NOT EXISTS 'host=MYSQL_SERVER user=MYSQL_USER password=PWD database=DATABASE' AS mysql1 (TYPE MYSQL);
-
PostgreSql extension:
ATTACH 'dbname=DATABASE user=PG_USER password=PWD host=PG_SERVER' AS pg1 (TYPE POSTGRES, READ_ONLY);
(INSTALL is not needed as postgres is an official extension and autoloaded)
These statements can be specified as Init SQL in the cube's configuration form; if you don't see this field, click "add init SQL" near Select Query caption). Then, you can use attached DB in the Select Query, say:
select o.* from mysql1 left join pg1.users u on (u.user_id=o.user_id)
Alternatively, it is possible to run queries on remote server and then use resultset in a similar manner:
SELECT * FROM mysql_query('mysql1', 'select * from orders') o
LEFT JOIN (
SELECT * FROM mysql_query('mysql2', 'SELECT * FROM users')
) u ON (u.user_id=o.user_id)
In addition to these DuckDB extensions SeekTable integrates custom cube_query table function that
can query any other cube and use the resultset in DuckDB SELECTs (see below).
How to query SeekTable cubes in DuckDB SQL
DuckDB connector can be used as a data federation engine for combining data from another cubes in a single SQL query.
For this purpose DuckDB connection string must be configured for in-memory mode (Data Source=:memory:, which is used when DuckDB connector operates in restricted mode)
and in this mode you can use a special cube_query SQL function that returns a tabular resultset (which can be used as a virtual 'table' in the DuckDB SQL):
SELECT * FROM cube_query('cube_id', '["dim1", "dim2"]', '{"param1":"val1"}')
This function has 3 arguments:
| # | Meaning | Description |
|---|---|---|
| 1 | cube ID | Another cube identifier (GUID) to query. Specified cube should be accessible in user's context:
if you share items based on this DuckDB cube, cubes used in cube_query calls should be shared too. |
| 2 | query JSON (string) | This can be either JSON array with the list of columns that refer to cube's dimensions/measures names:
'["dim1", "dim2"]'or JSON object with required Columns property and optional Offset / Limit:
'{"Columns":["dim1", "dim2"],"Limit":1000}'
When only dimension names are specified (as columns) cube executes non-aggregate query similar to "flat table" reports;
this kind of queries are not cached on SeekTable side and can return millions of rows.
If at least one column refers to a measure cube executes aggregate query similar to "pivot table" reports. Aggregation results are cached by default. |
| 3 | parameters JSON (string) | A JSON object with cube parameters. If you don't want to specify any parameters this argument can be an empty string ('').
You may use DuckDB cube parameter values in this JSON; to compose values in a safe manner (to avoid possibility of SQL injections) use function json_object that accepts arguments as key-value pairs, for example: cube_query('cube_id', '["dim1", "dim2"]', json_object("param1", "val1", "param2", @param2[{0};null] )
|
You can use multiple cube_query calls and combine results with UNION / JOIN / sub-SELECT as you need.
Use ATTACH DuckDB commands (can be specified via Init SQL) to query local database files.
Technical limitation: "Infer dimensions and measures by dataset" should be unchecked when DuckDB SQL query uses cube_query SQL function.
This means that all dimensions/measures should be configured manually.